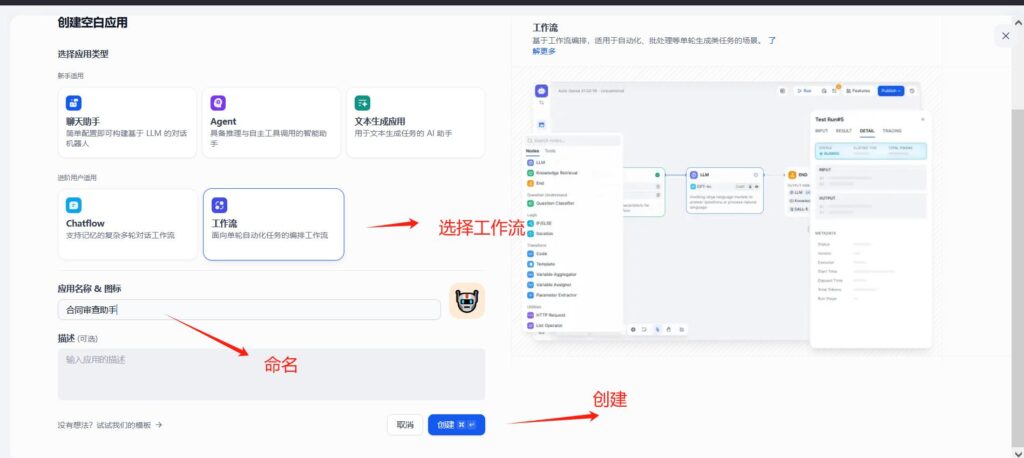
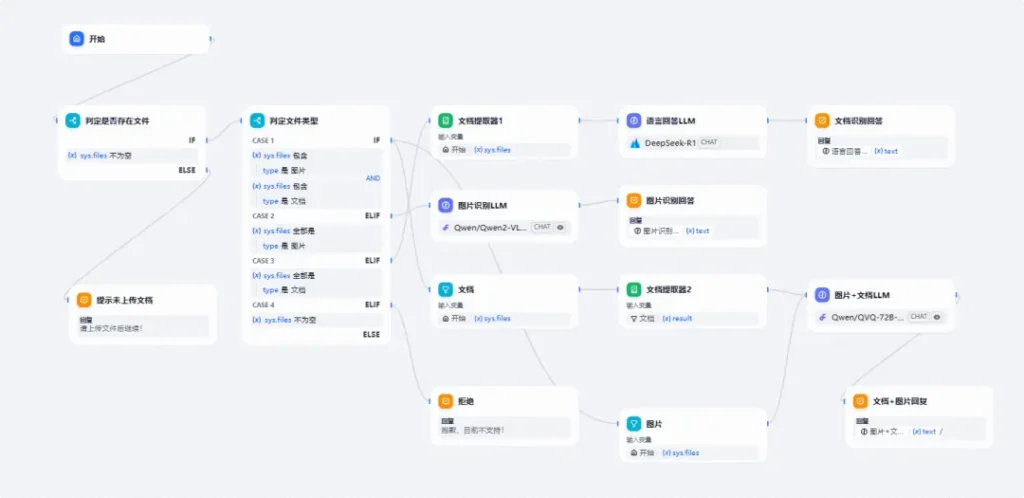
今天我们要用Chatflow来打造一款智能文档助手,下面来看看这个工作流的最终工作流程图吧:
以及我们上传一张图片,让LLM帮我们解析图片内容

好了,下面就跟着我来看看,如何实现吧!
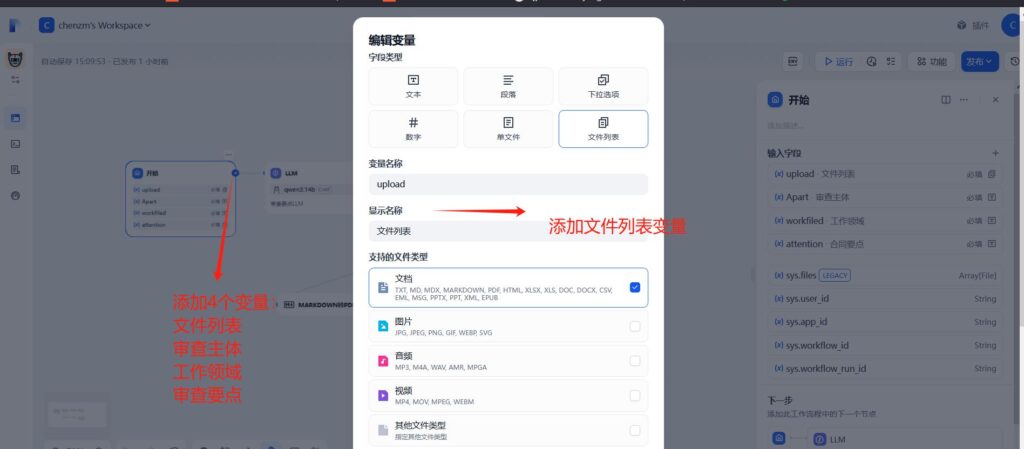
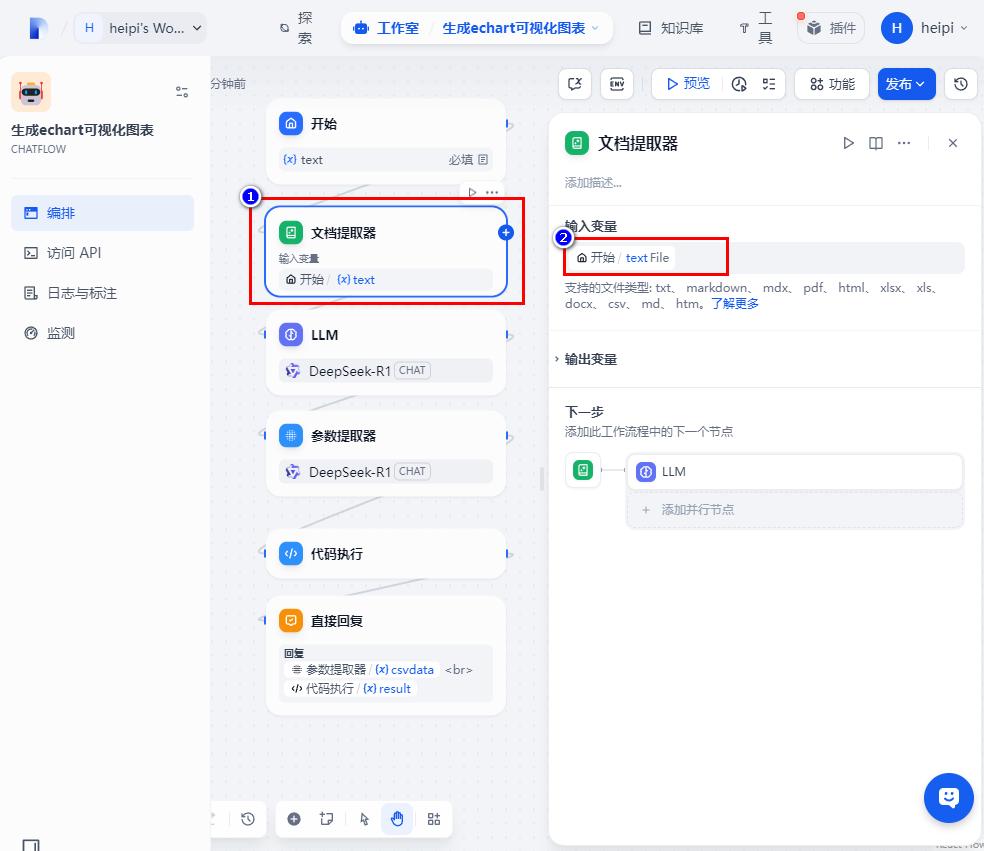
首先我们创建开始节点,这块我们就作为文件输入的节点就行,如果需要一些限定条件的,可以添加字段来做处理。
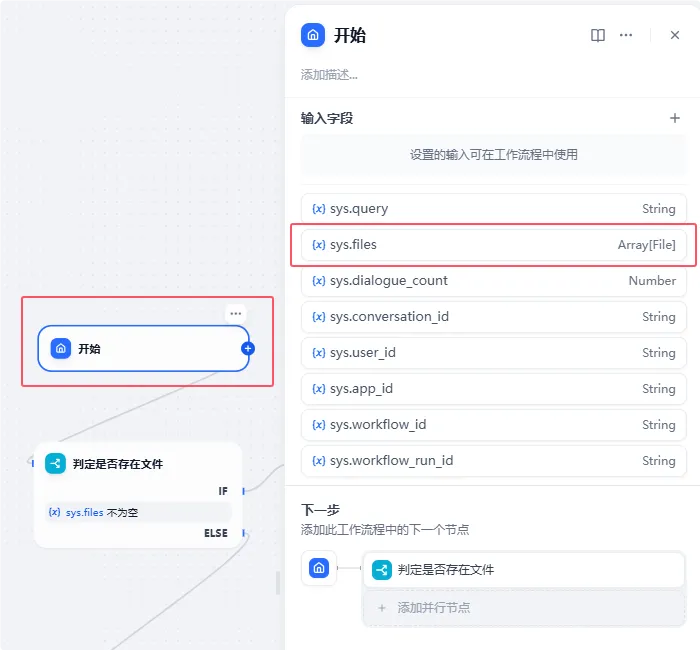
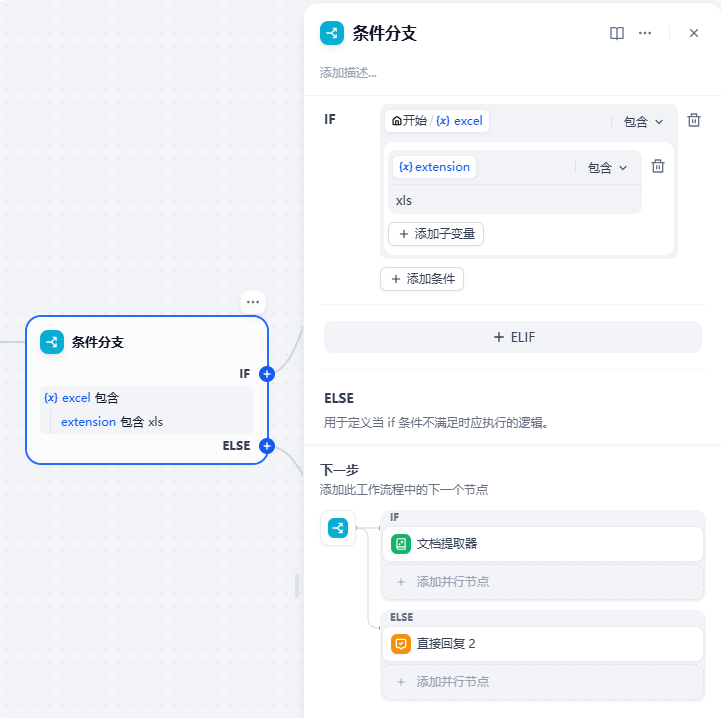
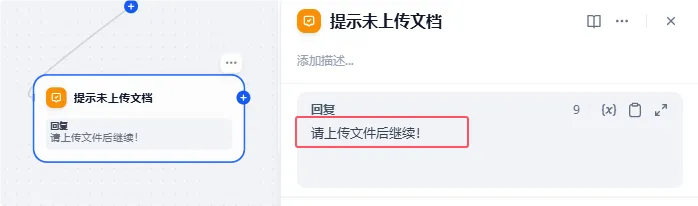
开始节点后,我们要去判断这一次对话是否有文件上传,如果有文件就前往下一个节点,如果没有问题,则提示“请上传文件后继续!”
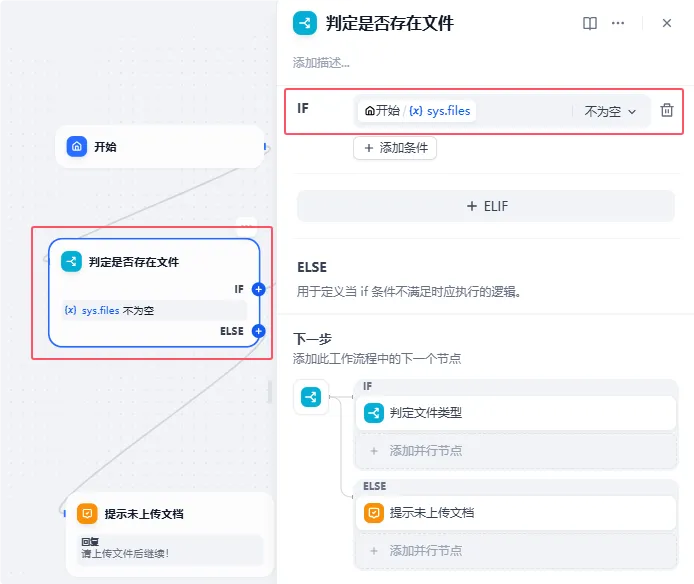
当前判断有文件后,我们进入下一个节点也就是判定文件类型节点中,这个节点就是用来筛选文件是全图片,还是全文档,亦或者是既有图片也有文档:
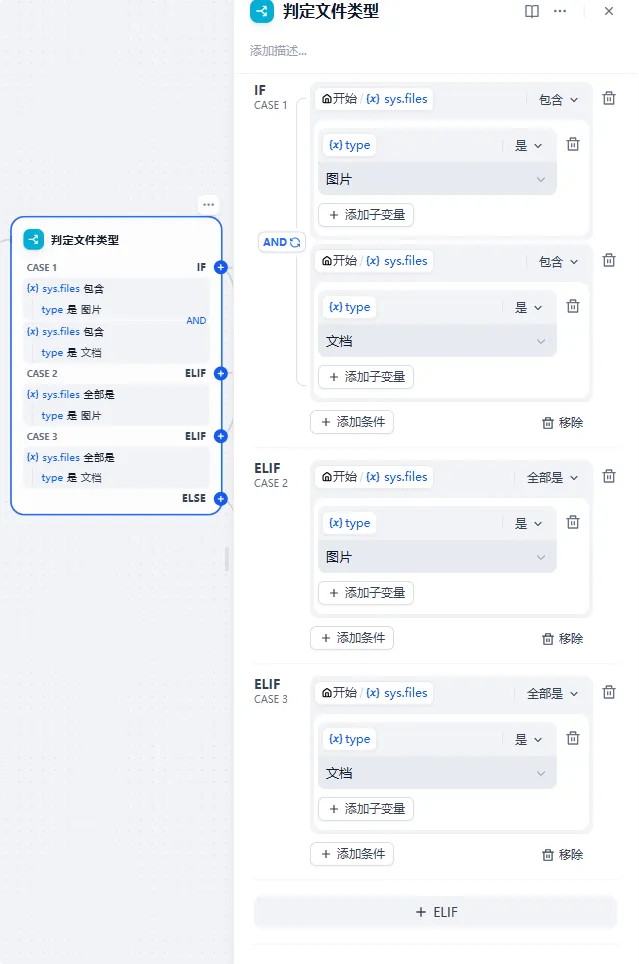
如果全是图片的话,我们下一个节点就到了【图片识别LLM】节点中去,此处我们使用Qwen2-VL-72B-Instruct这个支持多模态的大模型,需要在节点设置中打开视觉设置,确保LLM可以直接读取图片进行分析,并结合开始节点中,用户提出的问题进行回答:
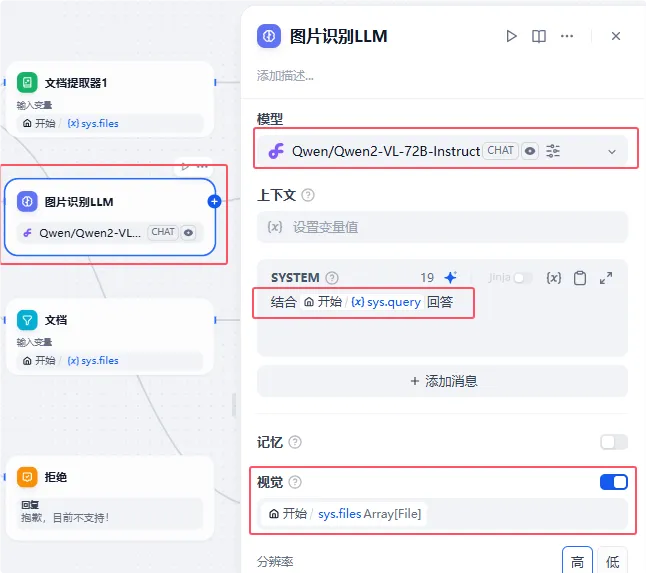
然后把结果输入到【图片识别回答】节点,进行内容输出:
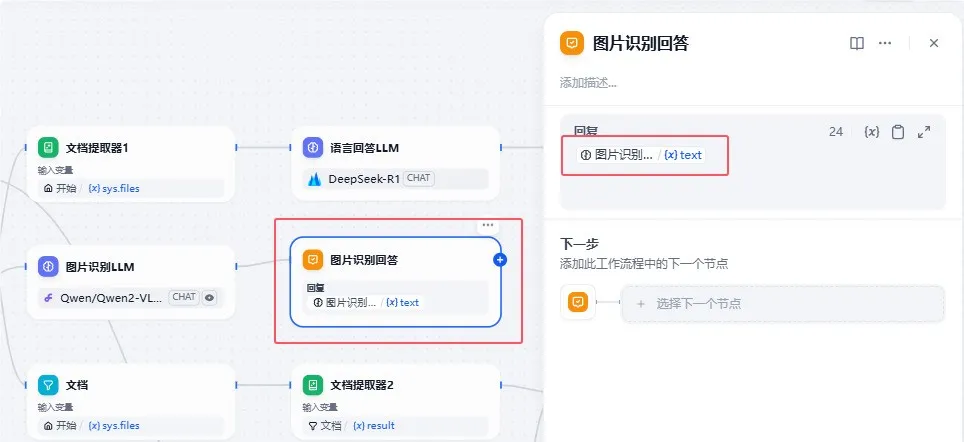
如果全是文档的话,则进入文档提取器节点,对文档内容进行提取:

然后传递给LLM并结合开始节点的用户输入内容进行分析解答:
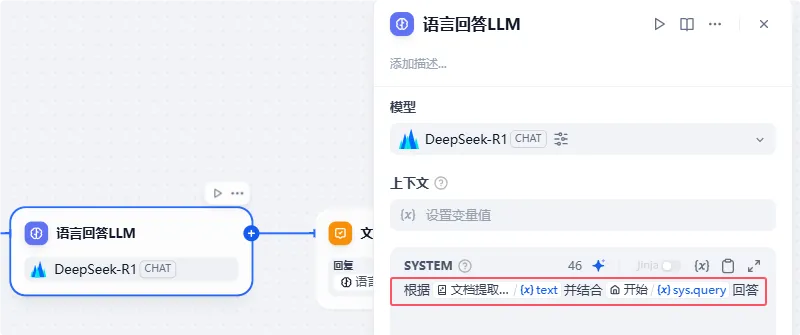
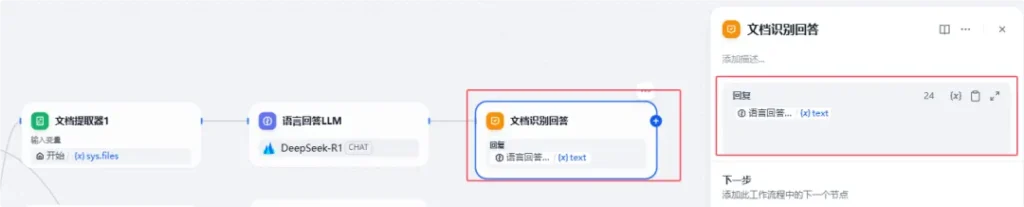
最后把LLM输出内容直接传递给【文档识别问答】节点,进行对用户操作结果的输出。
当上传的文件既有图片也有文档时,就需要用到【列表操作】节点,然后对开始节点上传的文件进行过滤,我们这边文档就拿xlsx类型进行过滤,然后把结果数组传递给【文档提取器】进行文档内容提取:
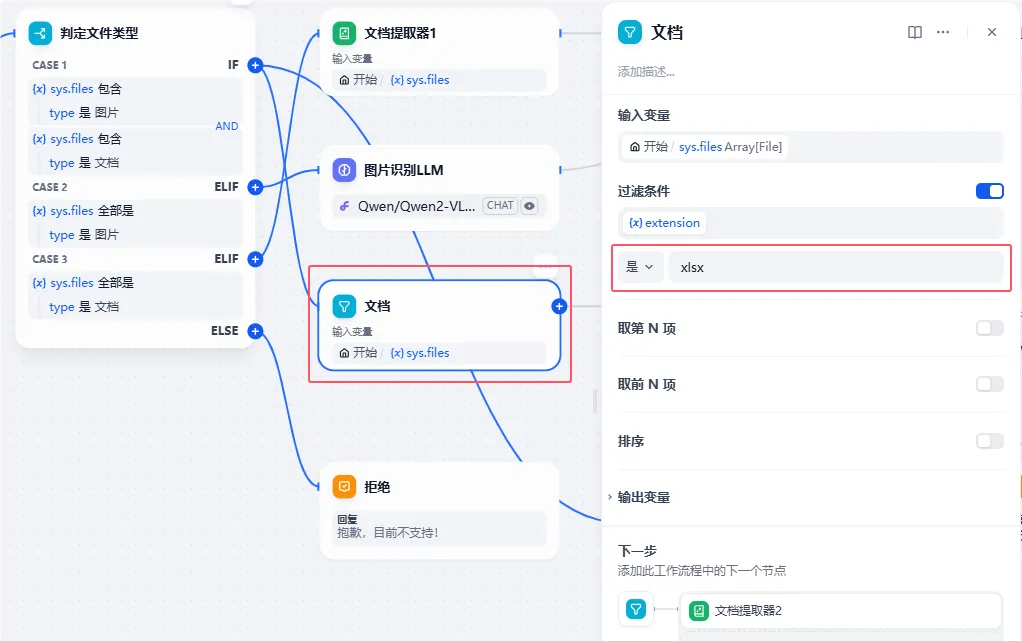
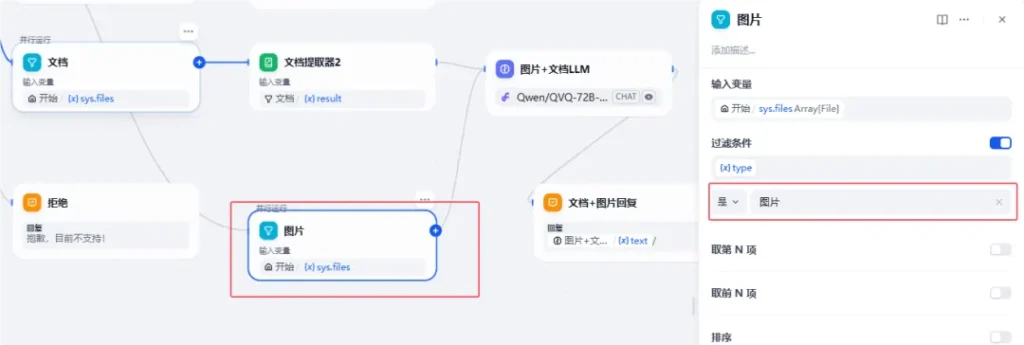
同样我们也用【列表操作】节点过滤图片:
然后把文档提取器和图片的输出内容都传递给【图片+文档LLM】节点,同样因为要处理图片,我们在此使用的LLM也是多模态的LLM:
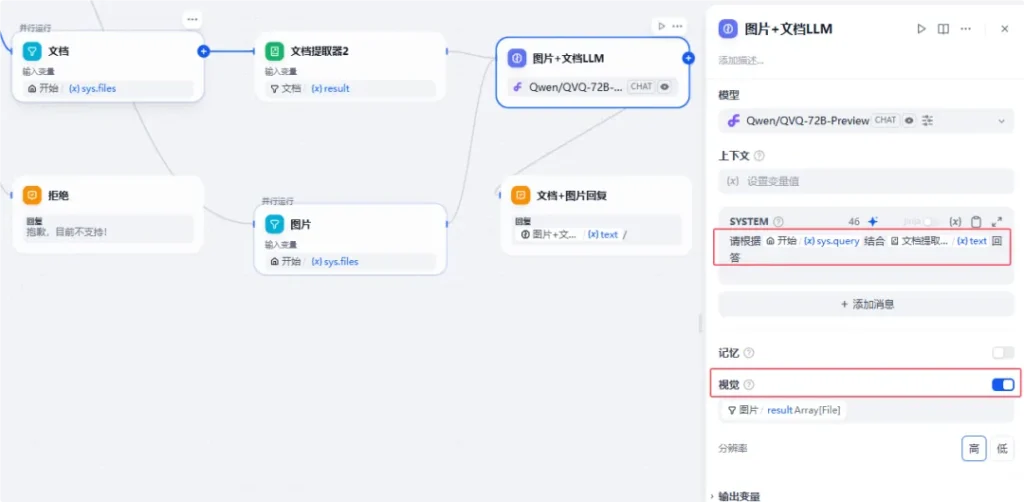
LLM根据用户输入的内容和前置文档提取器节点输出的内容以及图片数组,进行分析解答
当上面几个条件判断都不满足的时候,直接拒绝后续操作,提示“抱歉,目前不支持!”
好了,智能文档助手也介绍的差不多了,不过需要注意的是,这个demo只是一个比价简单的应用,需要根据你们的详细业务逻辑进行强化,对简单逻辑进行加强,复杂化。
转载作品,原作者:PM墨者,文章来源:https://mp.weixin.qq.com/s/b7dMzoCt4gGED1ArA4C7Pg