在大语言模型(LLM)微调的赛道上,“数据” 始终是绕不开的核心。无论是通用模型的垂直化适配,还是领域知识的定向注入,高质量、结构化的训练数据往往决定了模型最终的表现。但手动构建这样的数据集,却常被从业者戏称为 “体力活”—— 从文本清洗、内容分割,到问题生成、答案标注,每一步都需要大量时间与精力。
最近,笔者发现了一款名为 Easy Dataset 的开源工具,它精准瞄准了 “LLM 微调数据集创建” 这一痛点,以低门槛、高效率、强扩展性的特性,迅速成为开发者的 “数据助手”。本文将从实战角度,带你体验这款工具的核心功能与技术亮点。
一、开箱即用:从 “0” 到 “数据集” 的全流程体验
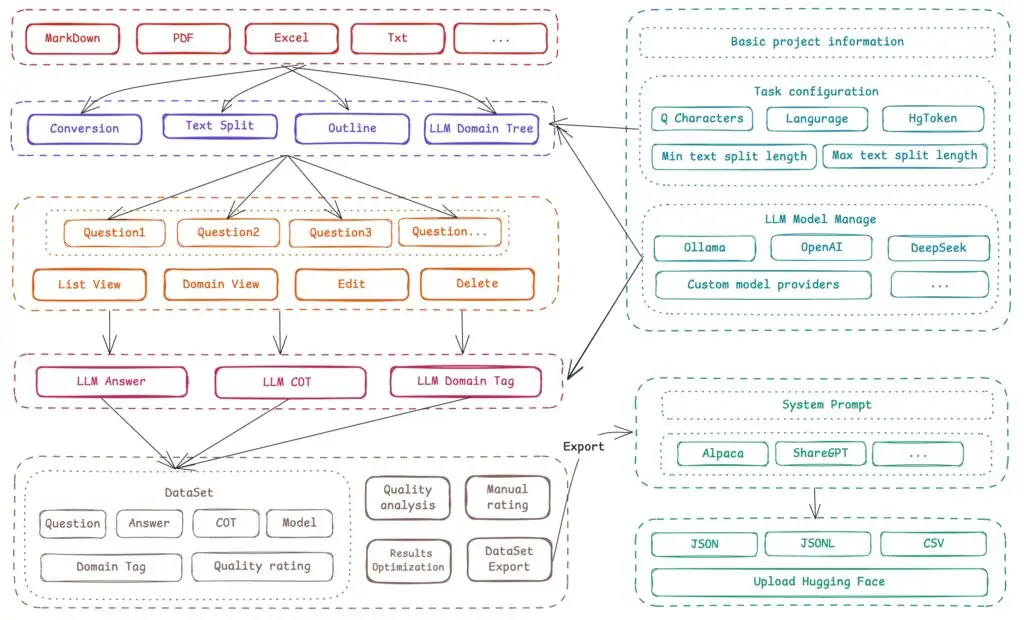
Easy Dataset 的定位非常明确:为 LLM 微调提供 “一站式数据集创建服务”。其界面设计简洁直观,即使是新手也能快速上手。我们以 “医疗领域知识微调” 为例,演示其核心流程:
1. 上传文件,智能分割内容
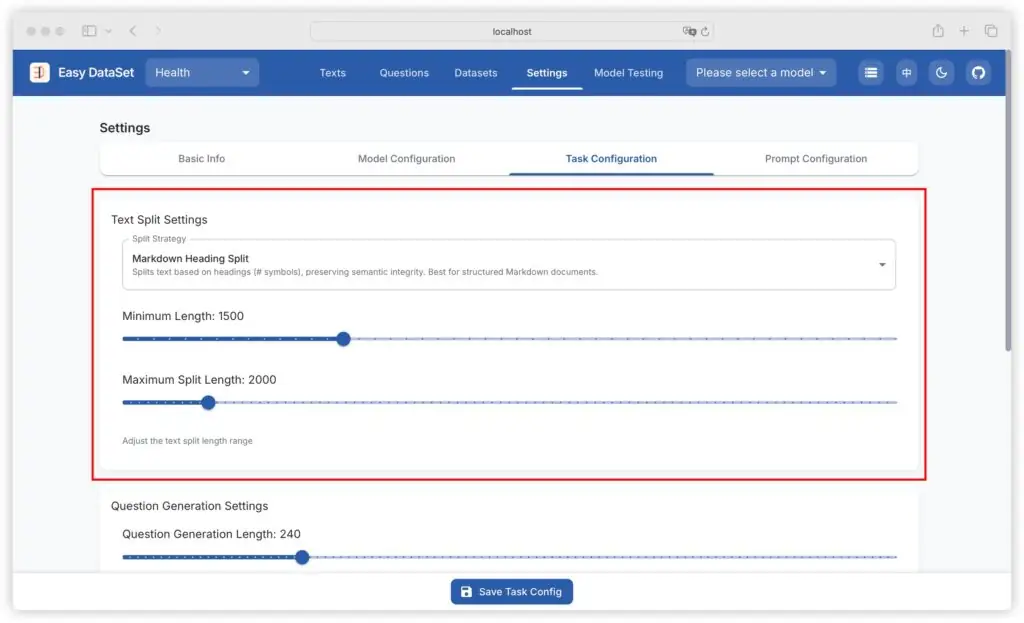
用户可直接上传领域文本(当前支持 TXT,未来计划扩展 PDF、DOC 等),工具会自动按语义或长度分割成 “文本块”(Chunk)。例如,上传一份 “糖尿病诊疗指南”,系统会将其拆分为 “病理机制”“诊断标准”“治疗方案” 等独立片段,避免长文本对模型生成的干扰。
2. 生成问题,覆盖知识要点
基于分割后的文本块,用户可一键调用预配置的 LLM(如 OpenAI、Ollama 等)生成问题。例如,针对 “诊断标准” 片段,工具可能生成:“糖尿病的主要诊断指标有哪些?”“空腹血糖的正常范围是多少?” 等问题。生成的问题支持人工编辑,确保覆盖关键知识。
3. 生成答案,优化数据质量
问题生成后,工具可再次调用 LLM 为每个问题生成答案(支持 “思维链” 优化)。例如,针对 “糖尿病的主要诊断指标”,系统会结合文本内容生成结构化答案,并自动记录答案来源的文本块,方便追溯与校验。生成的答案支持人工修改,确保数据准确性。
4. 导出数据集,适配主流 LLM
最终,用户可将整理好的 “问题 – 答案” 对导出为 OpenAI 格式(或未来支持的其他格式),直接用于模型微调。整个流程从 “上传文件” 到 “导出数据集”,最快仅需数十分钟,效率远超传统手动标注。
二、技术亮点:不止于 “工具” 的深度设计
Easy Dataset 的强大,不仅在于操作的 “傻瓜式”,更在于其底层的技术积累与扩展性设计:
1. 多模型兼容,灵活适配需求
工具支持接入多种 LLM(如 OpenAI、Ollama、智谱 AI 等),用户可通过配置 API 密钥或地址,自由选择模型。例如,若需要低成本生成,可选择本地部署的 Ollama;若追求高精度,可调用 OpenAI 的 GPT-4。这种灵活性,让不同资源条件的开发者都能找到合适的生成方案。
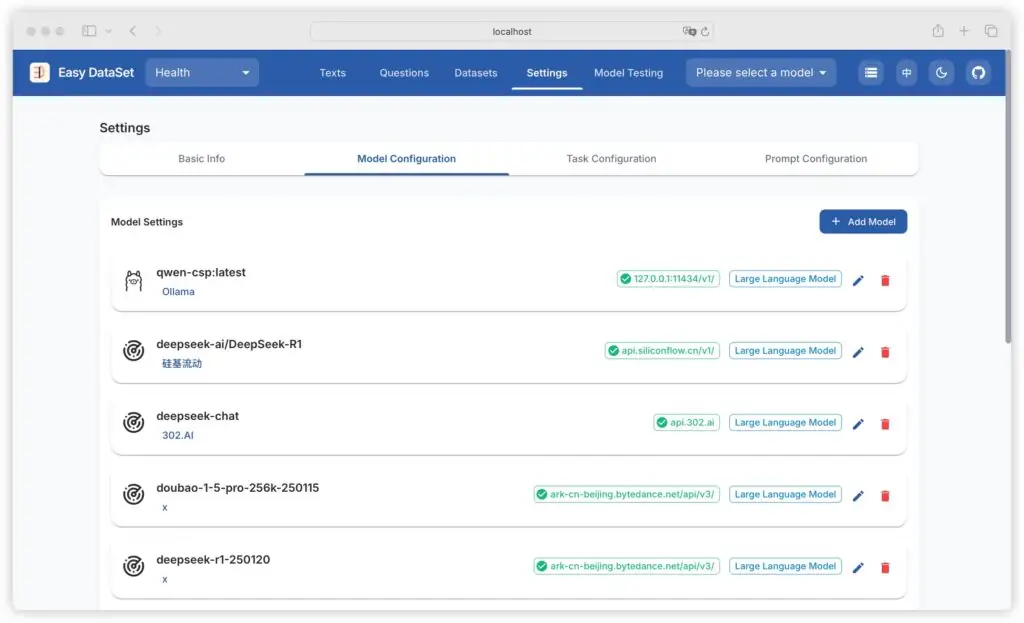
2. 数据管理模块,全生命周期追踪
工具内置 “数据集管理” 功能,支持对生成的问题、答案进行筛选、编辑、标注(如标记 “已确认”“待优化”),并提供分页查询、关键词搜索等功能。此外,每个数据项均记录了生成时间、关联文本块、使用的模型等元信息,方便后续分析与优化。
3. 开源可扩展,社区驱动进化
作为 AGPL 协议的开源项目,Easy Dataset 的代码完全开放(架构文档详细记录了模块设计),开发者可根据需求二次开发。例如,可扩展支持更多文件格式(如 Markdown、CSV),或集成自研的 LLM 生成策略。目前社区已贡献了 “数据集版本管理”“团队协作” 等未来规划,潜力巨大。
三、实战总结:为什么值得尝试?
对于需要 LLM 微调的开发者或团队,Easy Dataset 的价值可总结为三点:
- 降本:自动化生成替代人工标注,大幅减少数据制作时间(实测效率提升 80%+);
- 提质:LLM 生成 + 人工校验的模式,确保数据覆盖度与准确性;
- 灵活:多模型支持、开源可扩展,适配不同场景与技术栈。
目前,工具已在 “领域知识注入”(如法律、医疗)、“垂类对话模型训练” 等场景中验证了效果。社区还提供了演示视频与详细文档,新手可快速入门。
四、安装和使用
目前 Easy Dataset 支持客户端、NPM、Docker 三种启动方式,所有启动方式均完全在本地处理数据,无需担心数据隐私问题。
客户端启动(适合新手)
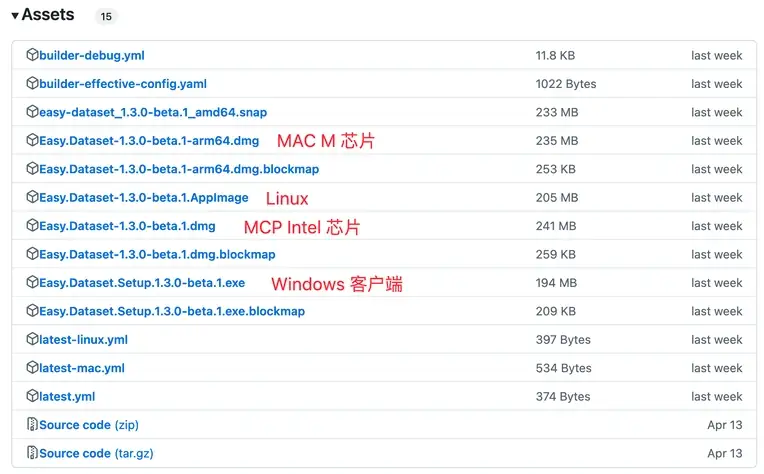
为了解决各种本地部署的环境问题,可以直接用客户端启动,支持以下平台:

可以直接到 https://github.com/ConardLi/easy-dataset/releases 下载适合自己系统的安装包:
如果遇到 Github 下载较慢,可以使用网盘下载:https://pan.quark.cn/s/ef8d0ef3785a
NPM 启动(适合开发者)
本项目基于 Next 构建,所以本地只要有 Node 环境就可以通过 NPM 直接启动,适合开发者,需要调试项目的同学:
克隆仓库:
git clone https://github.com/ConardLi/easy-dataset.git
cd easy-dataset安装依赖:
npm install启动服务器:
npm run build
npm run start注意:使用 NPM 启动的情况下,当系统发布新版本后,需要重新执行 git pull 拉取最新代码,并且重新执行 npm install、npm run build、npm run start 三个步骤。
Docker启动(适合私有部署)
如果你想自行构建镜像,在云服务或者内网环境私有部署,可以使用项目根目录中的 Dockerfile:
克隆仓库:
git clone https://github.com/ConardLi/easy-dataset.git
cd easy-dataset构建 Docker 镜像:
docker build -t easy-dataset .运行容器:
docker run -d -p 1717:1717 -v {YOUR_LOCAL_DB_PATH}:/app/local-db --name easy-dataset easy-dataset注意: 请将 {YOUR_LOCAL_DB_PATH} 替换为你希望存储本地数据库的实际路径。
Github:https://github.com/ConardLi/easy-dataset
Easy Dataset 产品简介:https://docs.easy-dataset.com/
原创文章,作者:howkunet,如若转载,请注明出处:https://www.intoep.com/ai/66932.html