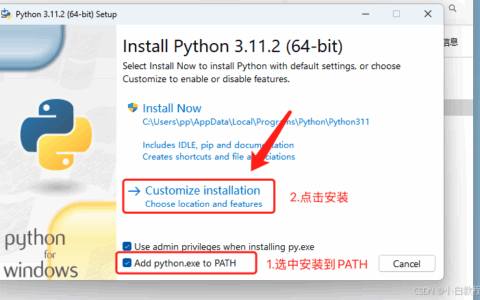
环境准备
1. With pip (Python>=3.11)
2. 安装 Browser Use
bash
pip install browser-use3. 安装 Install Playwright
bash
playwright install chromium4. 创建 .env 文件填入API-key
OPENAI_API_KEY=
DEEPSEEK_API_KEY=《你的api-key》
DASHSCOPE_API_KEY=《你的api-key》
ANTHROPIC_API_KEY=
GEMINI_API_KEY=《你的api-key》
OLLAMA_HOST=https://127.0.0.1:11434 #本地ollama模型- 爬虫代码(参考-请修改对应大模型平台的base_url)
- 这里以阿里百炼平台为例
import asyncio
import os
import csv
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_ollama import ChatOllama
from pydantic import SecretStr
from browser_use import Agent, Controller
from browser_use.agent.views import ActionResult
from browser_use import BrowserConfig, Browser
from openai import OpenAI
# dotenv
load_dotenv()
api_key = os.getenv('DASHSCOPE_API_KEY', '')
if not api_key:
raise ValueError('DEEPSEEK_API_KEY is not set')
# 公共参数
commons={
"qds":"1100048",
"qdn":"重庆机场集团有限公司",
"data_source_type":"招投标",
"page_index":"首页>采购公告",
}
controller = Controller()
@controller.registry.action('保存结果到指定文件')
def save_to_file(text: str, file_path: str):
with open(file_path, 'w', encoding='utf-8') as f:
f.write(text)
return ActionResult(extracted_content=f"已保存内容到文件: {file_path}")
@controller.registry.action('保存CSV数据')
def save_csv_data(data: list, file_path: str):
"""
保存数据到CSV文件
Args:
data: 包含字典的列表,每个字典代表一行数据
file_path: 保存的文件路径
"""
if not data:
return ActionResult(extracted_content="没有数据可保存")
# 确保data是列表格式
if not isinstance(data, list):
data = [data]
# 获取所有可能的字段名
fieldnames = set()
for item in data:
if isinstance(item, dict):
fieldnames.update(item.keys())
fieldnames = list(fieldnames)
with open(file_path, 'w', encoding='utf-8', newline='') as f:
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
for item in data:
if isinstance(item, dict):
writer.writerow(item)
return ActionResult(extracted_content=f"已成功保存{len(data)}条记录到CSV文件: {file_path}")
@controller.registry.action('追加CSV数据')
def append_csv_data(data: list, file_path: str):
"""
追加数据到CSV文件,如果文件不存在则创建
Args:
data: 包含字典的列表,每个字典代表一行数据
file_path: 保存的文件路径
"""
if not data:
return ActionResult(extracted_content="没有数据可保存")
# 增加调试信息
print(f"接收到的数据类型: {type(data)}")
print(f"数据内容: {data}")
# 确保data是列表格式
if not isinstance(data, list):
try:
# 尝试将字符串转换为列表
import json
if isinstance(data, str):
data = json.loads(data)
except Exception as e:
print(f"数据转换失败: {str(e)}")
data = [data]
# 获取所有可能的字段名
fieldnames = set()
for item in data:
if isinstance(item, dict):
fieldnames.update(item.keys())
fieldnames = list(fieldnames)
# 检查文件是否存在
file_exists = os.path.isfile(file_path)
try:
with open(file_path, 'a', encoding='utf-8', newline='') as f:
writer = csv.DictWriter(f, fieldnames=fieldnames)
# 如果文件不存在,写入表头
if not file_exists:
writer.writeheader()
# 写入数据
for item in data:
if isinstance(item, dict):
writer.writerow(item)
return ActionResult(extracted_content=f"已成功追加{len(data)}条记录到CSV文件: {file_path}")
except Exception as e:
error_msg = f"写入CSV文件时出错: {str(e)}"
print(error_msg)
return ActionResult(extracted_content=error_msg)
async def run_search():
# Basic configuration
config = BrowserConfig(
headless=False,
disable_security=True,
)
browser = Browser(config=config)
# 简化任务描述,使其更加明确
task_description = (
"打开 https://zc.cqa.cn/eip/websit/index.do "
"获取前3页的采购公告列表中的所有公告,获取每条公告的详情页链接,公告标题,公告时间。"
"对于每条公告,提取以下字段:'标题'、'发布时间'、'详情链接'。"
"将该页数据整理成列表格式,列表中每个公告是一个字典,包含上述三个字段。"
"重要:每采集完一页数据后,立即使用'追加CSV数据'工具将该页数据追加到文件'采购公告-2025-03-07.csv'中,然后再继续采集下一页。"
"具体步骤如下:"
"1. 打开网站后,找到采购公告列表"
"2. 获取当前页的所有公告数据(标题、发布时间、详情链接)"
"3. 使用'追加CSV数据'工具将当前页的数据追加到CSV文件"
"4. 点击'下一页'按钮,进入下一页"
"5. 重复步骤2-4,直到采集完前3页的数据"
)
agent = Agent(
browser=browser,
task=task_description,
llm=ChatOpenAI(
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
model='qwq-32b',
streaming=True,
api_key=SecretStr(api_key),
temperature=0.1, # 降低温度,使输出更确定性
max_tokens=4096,
model_kwargs={
"response_format": {"type": "text"}
},
),
max_actions_per_step=1, # 每步只执行一个动作
controller=controller,
use_vision=True, # 启用视觉能力,帮助更好地理解页面
tool_calling_method="raw",
)
try:
result = await agent.run()
print("任务完成,结果:", result)
return result
except Exception as e:
error_msg = f"任务执行出错: {str(e)}"
print(error_msg)
return error_msg
if __name__ == '__main__':
asyncio.run(run_search())- 执行过程
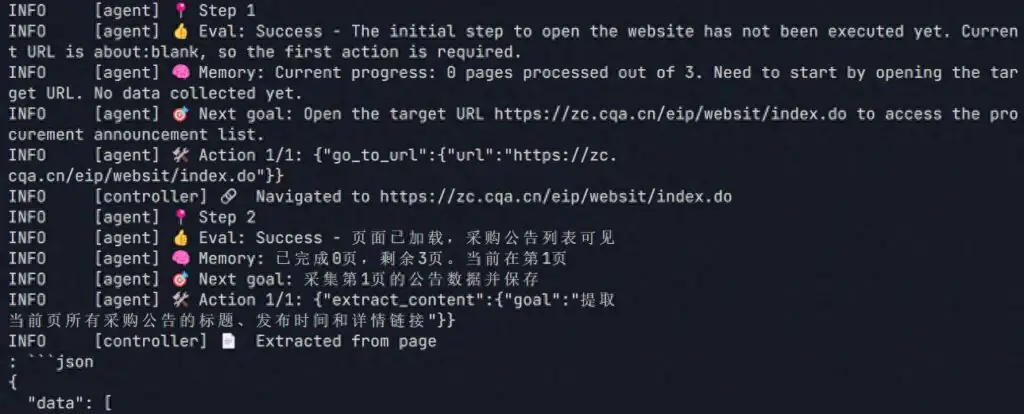
- csv数据
转载作品,原作者:小和美,文章来源:https://www.toutiao.com/article/7496106358580773426