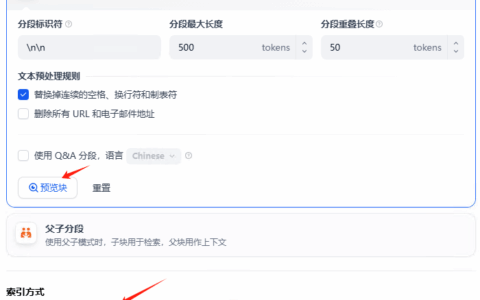
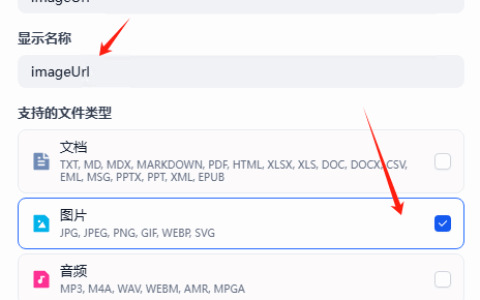
最近在推进 dify 智能客服应用时,客服团队又提出了一个新需求:
“我们的用户手册都是图文并茂的,有些操作单靠文字根本讲不清楚,能不能也让智能客服的回答里带上图片?”
这个问题其实在很多企业的知识库中都存在。纯文字的知识点,在面对设备操作、软件配置、页面引导等任务时,往往力不从心。图片不仅能直观表达,更能减少沟通成本,提升用户满意度。
常规思路:用 http 节点拼图,但有点麻烦
一开始,我考虑的是通过 dify 的工作流功能来实现图文混排:
- 我们知识库中存储的图片链接有两种格式( <img>或 ![image] 标签)。
- 利用 参数提取器节点从答案中提取图片链接。
- 在工作流中加入 HTTP 请求节点,拉取图片后,在回答内容末尾拼接上去,再一起发给用户。

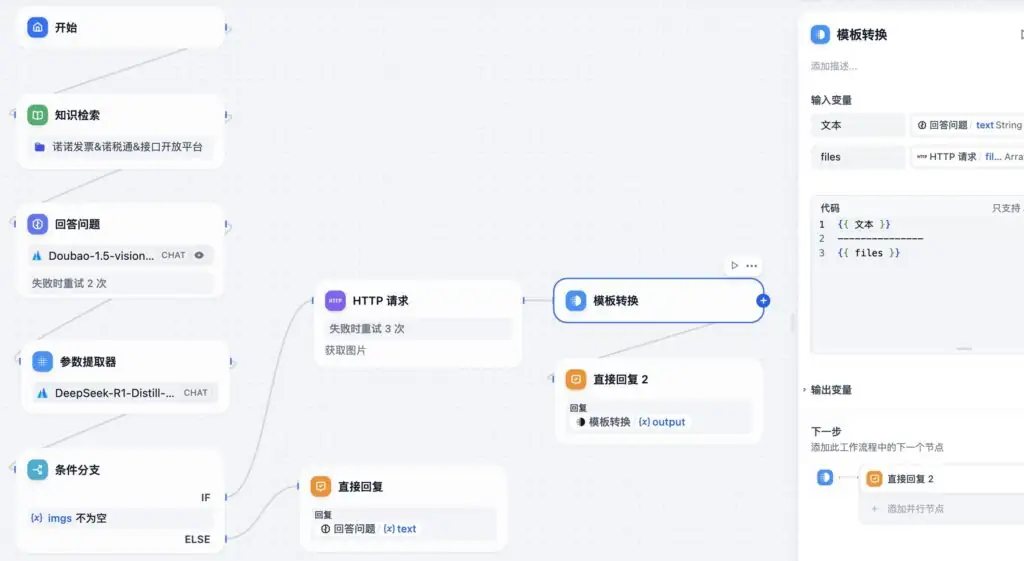
虽然技术上可行,但实测下来体验并不好:
- ❌ 工作流太复杂,每次都要提取+拼接。
- ❌ 响应时间拉长,需要等 HTTP 请求完成后,才能一起输出答案。
- ❌ 效果一般,只能把图片放在回答后面,不能真正做到“图文混排”。
于是我开始反思:既然用流程拼接图片不理想,能不能直接让大模型自己理解图文?
灵机一动:让大模型直接“识图识文”!
我突然意识到:大模型在对 HTML、Markdown 等结构文本有很强的解析能力,既然如此,大模型是否可以自己解析并输出图文混排效果?
马上开始调整:
✅ 微调提示词(Prompt)
在回答提示词中加了一句引导语:
如答案有图片<img>、,显示图片。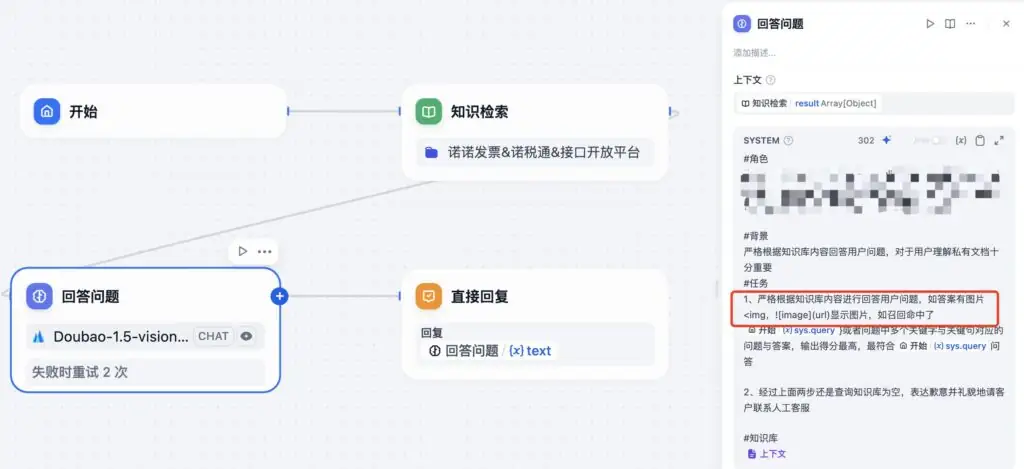
✅ 验证效果:完美!
经过测试,模型在回答中不仅正确引用了知识库的图文内容,还保持了清晰的图文排版结构。
通过简单地优化提示词,不仅大大简化了工作流,完美解决了图文混排的效果,还能保持答案的流式输出效果,客服反馈体验提升明显。
转载作品,原作者:,文章来源:https://www.toutiao.com/article/7494196562466243113