摘要
本文介绍了如何利用 PaddleOCR 实现对 PDF 文件或图片 的文字识别,并在识别后将文本内容按照 原始版面位置 进行还原重建。文章详细讲解了实现流程,包括 图像预处理、OCR 识别、版面坐标提取与重排、以及最终生成 可编辑的 PDF 或可视化输出 的过程。
本文将带你使用 PaddleOCR 实现一个完整流程:
安装方法
# gpu方法自己百度
# 升级 pip
python -m pip install --upgrade pip
# 设置清华源加速下载(可选)
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
# 安装 PaddlePaddle CPU 版本
python -m pip install paddlepaddle==3.2.0 -i https://www.paddlepaddle.org.cn/packages/stable/cpu/
# 安装辅助库
python -m pip install PyMuPDF Pillow reportlab tqdm beautifulsoup4
# 安装指定版本 PaddleOCR
python -m pip install paddleocr==3.2.0目录结构
字体自行下载
└─$ tree
.
├── fonts
│ └── simsun.ttf
├── main.py
├── pdf_ocr_select.py
└── thread_single.pythread_single.py
from paddleocr import PaddleOCR
import os
import logging
import time
from concurrent.futures import ThreadPoolExecutor, TimeoutError
import paddle
class PaddleOCRModelManager(ThreadPoolExecutor):
def get_device(self):
try:
if paddle.is_compiled_with_cuda() and paddle.device.cuda.device_count() > 0:
self.logger.info("检测到可用 GPU,多线程模式下启用 GPU 加速")
return "gpu:0"
except Exception as e:
self.logger.warning(f"GPU 检测失败: {e}")
self.logger.info("使用 CPU 进行 OCR")
return "cpu"
def __init__(self, current_app, **kwargs):
# 增加线程池大小并设置线程名称
super(PaddleOCRModelManager, self).__init__(max_workers=1, thread_name_prefix="paddle_ocr_", **kwargs)
os.environ["PADDLE_PDX_CACHE_HOME"] = "./module"
self.logger = current_app.logger
self.logger.info("初始化PaddleOCR模型管理器...")
try:
self.paddleocr = PaddleOCR(
text_detection_model_name="PP-OCRv5_server_det",
text_recognition_model_name="PP-OCRv5_server_rec",
use_doc_orientation_classify=False,
use_doc_unwarping=False,
use_textline_orientation=False,
device=self.get_device()
)
self.logger.info("PaddleOCR模型初始化成功")
except Exception as e:
self.logger.error(f"PaddleOCR模型初始化失败: {str(e)}")
raise
self.app = current_app
self.active_tasks = 0
def submit_ocr(self, **kwargs):
self.active_tasks += 1
self.logger.info(f"提交OCR任务,当前活跃任务数: {self.active_tasks}")
try:
# 添加超时参数,防止单个任务阻塞过长时间
future = self.submit(self.infer, **kwargs)
result = future.result(timeout=600) # 设置10分钟超时
return result
except TimeoutError:
self.logger.error(f"OCR任务执行超时")
raise TimeoutError("OCR处理超时,请检查输入图像质量和服务器负载")
except Exception as e:
self.logger.error(f"OCR任务执行异常: {str(e)}")
raise
finally:
self.active_tasks -= 1
self.logger.info(f"OCR任务完成,当前活跃任务数: {self.active_tasks}")
def infer(self, **kwargs):
start_time = time.time()
input_path = kwargs.get('input', '')
json_path = kwargs.get('json_path', '')
self.logger.info(f"开始OCR推理,输入: {input_path}")
try:
result_str = self.paddleocr.predict(input_path)
processing_time = time.time() - start_time
self.logger.info(f"OCR推理完成,处理时间: {processing_time:.2f}秒")
result = self.print_order_no(result_str,json_path)
self.logger.info(f"OCR推理结果: {result}")
return result, result_str
except Exception as e:
self.logger.error(f"OCR推理异常: {str(e)}")
raise
def print_order_no(self, result,json_path):
res_str = ""
try:
for res in result:
res.save_to_json(json_path)
self.logger.info(f"OCR结果处理完成,识别文本数: {sum(len(res['rec_texts']) for res in result)}")
return res_str
except Exception as e:
self.logger.error(f"OCR结果处理异常: {str(e)}")
raisemain.py
from fastapi import FastAPI, UploadFile, HTTPException, Form
from fastapi.responses import HTMLResponse, StreamingResponse, FileResponse
import os
import uuid
import subprocess
import json
import time
import shutil
BASE = "."
PDF_DIR = os.path.abspath("temp/input_pdfs")
OUT_DIR = os.path.abspath("temp/output_pdfs")
PROGRESS_DIR = os.path.abspath("temp/progress")
PAGES_DIR = os.path.abspath("temp/pdf_pages")
UPLOAD_DIR = os.path.abspath("temp/uploads")
for d in [PDF_DIR, OUT_DIR, PROGRESS_DIR, PAGES_DIR, UPLOAD_DIR]:
os.makedirs(d, exist_ok=True)
app = FastAPI(title="PaddleOCR PDF 可搜索化服务")
# ================== 前端单页 ==================
@app.get("/", response_class=HTMLResponse)
def index():
return """
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0"/>
<title>PaddleOCR PDF - 制作可搜索PDF</title>
<!-- Element Plus -->
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/element-plus@2.9.7/dist/index.css" />
<script src="https://cdn.jsdelivr.net/npm/vue@3/dist/vue.global.prod.js"></script>
<script src="https://cdn.jsdelivr.net/npm/element-plus@2.9.7/dist/index.full.min.js"></script>
<!-- Element Plus Icons -->
<script src="https://cdn.jsdelivr.net/npm/@element-plus/icons-vue@2.3.2"></script>
<!-- PDF.js -->
<script src="https://cdn.jsdelivr.net/npm/pdfjs-dist@3.11.174/build/pdf.min.js"></script>
<style>
body {
font-family: system-ui, -apple-system, sans-serif;
background:#f5f7fa;
margin:0;
padding:20px;
}
#app {
max-width:1400px;
margin:0 auto;
background:white;
padding:40px;
border-radius:16px;
box-shadow:0 4px 20px rgba(0,0,0,0.1);
}
.header { text-align:center; margin-bottom:40px; }
.upload-area { text-align:center; padding:40px 0; }
.progress-box { margin:32px 0; }
.result-box { margin-top:40px; text-align:center; }
/* 页面选择样式 */
.page-select-container {
margin: 20px 0;
max-height: 300px;
overflow-y: auto;
border: 1px solid #dcdfe6;
border-radius: 8px;
padding: 15px;
}
.page-select-header {
display: flex;
justify-content: space-between;
align-items: center;
margin-bottom: 15px;
padding-bottom: 10px;
border-bottom: 1px solid #ebeef5;
}
.page-list {
display: flex;
flex-wrap: wrap;
gap: 10px;
}
.page-item {
position: relative;
width: 100px;
cursor: pointer;
border: 2px solid transparent;
border-radius: 6px;
overflow: hidden;
transition: all 0.3s;
}
.page-item:hover {
border-color: #409eff;
}
.page-item.selected {
border-color: #409eff;
box-shadow: 0 0 0 2px rgba(64, 158, 255, 0.2);
}
.page-item img {
width: 100%;
height: 140px;
object-fit: cover;
display: block;
}
.page-item .page-num {
position: absolute;
bottom: 0;
left: 0;
right: 0;
background: rgba(0,0,0,0.6);
color: white;
text-align: center;
padding: 4px;
font-size: 12px;
}
.page-item .check-icon {
position: absolute;
top: 5px;
right: 5px;
background: #409eff;
color: white;
border-radius: 50%;
width: 20px;
height: 20px;
display: flex;
align-items: center;
justify-content: center;
font-size: 12px;
}
/* 实时预览样式 */
.preview-container {
margin-top: 30px;
}
.preview-header {
display: flex;
justify-content: space-between;
align-items: center;
margin-bottom: 15px;
}
.preview-layout {
display: grid;
grid-template-columns: 1fr 1fr;
gap: 20px;
height: 600px;
}
.preview-panel {
border: 1px solid #dcdfe6;
border-radius: 8px;
overflow: hidden;
display: flex;
flex-direction: column;
}
.preview-panel-header {
background: #f5f7fa;
padding: 10px 15px;
font-weight: bold;
border-bottom: 1px solid #dcdfe6;
display: flex;
justify-content: space-between;
align-items: center;
}
.preview-content {
flex: 1;
overflow: auto;
display: flex;
align-items: center;
justify-content: center;
background: #f0f0f0;
}
.preview-content img {
max-width: 100%;
max-height: 100%;
object-fit: contain;
}
#pdf-canvas {
max-width: 100%;
max-height: 100%;
}
/* 页面导航 */
.page-nav {
display: flex;
align-items: center;
gap: 10px;
}
.page-nav input {
width: 60px;
text-align: center;
}
</style>
</head>
<body>
<div id="app">
<div class="header">
<h2>PaddleOCR PDF</h2>
<p style="color:#666;">上传 PDF → OCR 识别 → 生成可搜索 PDF</p>
</div>
<!-- 上传区 -->
<div class="upload-area" v-if="step === 'upload'">
<el-upload
:auto-upload="false"
:limit="1"
accept=".pdf"
:on-change="handleFileChange"
>
<el-button type="primary" size="large">
<el-icon style="margin-right:6px"><Upload /></el-icon>
选择 PDF 文件
</el-button>
</el-upload>
</div>
<!-- 页面选择和配置区 -->
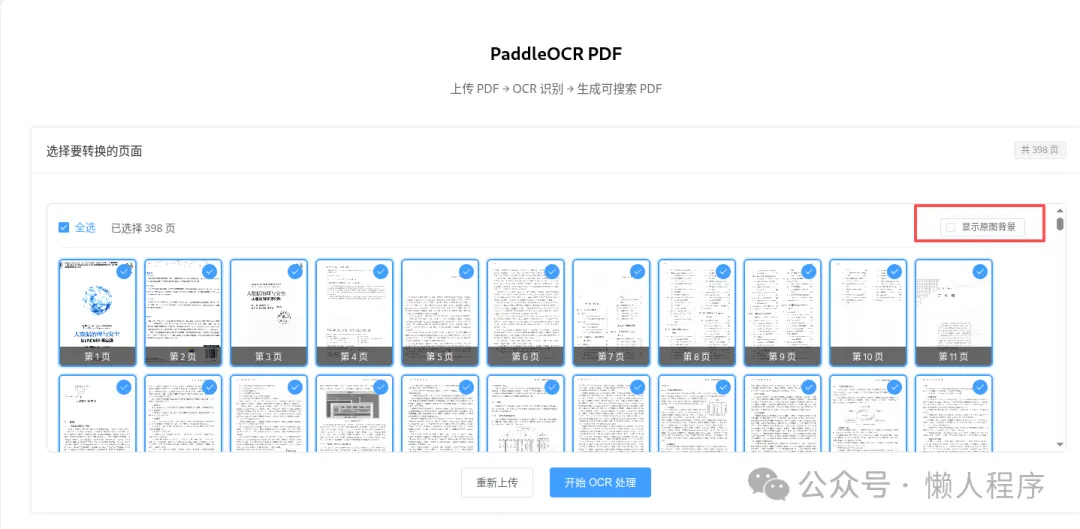
<div v-if="step === 'select' && pages.length > 0">
<el-card shadow="hover">
<template #header>
<div style="display:flex; justify-content:space-between; align-items:center;">
<span>选择要转换的页面</span>
<el-tag type="info">共 {{ pages.length }} 页</el-tag>
</div>
</template>
<!-- 页面选择 -->
<div class="page-select-container">
<div class="page-select-header">
<div style="display: flex; align-items: center; gap: 20px;">
<el-checkbox v-model="selectAll" @change="handleSelectAll">全选</el-checkbox>
<span style="color: #666; font-size: 14px;">已选择 {{ selectedPages.length }} 页</span>
</div>
<div style="display: flex; align-items: center; gap: 8px;">
<el-checkbox v-model="isVisible" size="small" border>
显示原图背景
</el-checkbox>
<el-tooltip content="勾选后生成的PDF保留原图背景,文字几乎透明但可搜索复制;不勾选则为纯白背景黑字" placement="top">
<el-icon style="color: #909399; cursor: help;"><QuestionFilled /></el-icon>
</el-tooltip>
</div>
</div>
<div class="page-list">
<div
v-for="page in pages"
:key="page.num"
class="page-item"
:class="{ selected: selectedPages.includes(page.num) }"
@click="togglePage(page.num)"
>
<img :src="page.thumb" :alt="'Page ' + page.num">
<div class="page-num">第 {{ page.num }} 页</div>
<div v-if="selectedPages.includes(page.num)" class="check-icon">
<el-icon><Check /></el-icon>
</div>
</div>
</div>
</div>
<!-- 操作按钮 -->
<div style="text-align: center; margin-top: 20px;">
<el-button size="large" @click="reset" style="margin-right: 10px;">重新上传</el-button>
<el-button
type="primary"
size="large"
@click="startOcr"
:disabled="selectedPages.length === 0"
>
开始 OCR 处理
</el-button>
</div>
</el-card>
</div>
<!-- 进度和预览区 -->
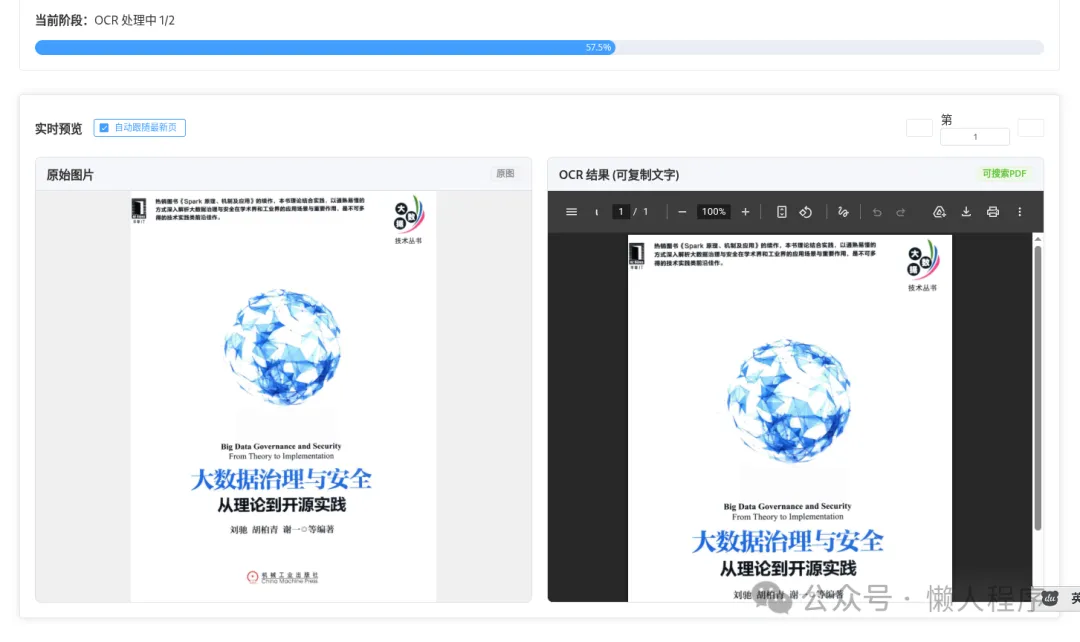
<div v-if="step === 'processing' || step === 'done'">
<el-card shadow="hover" class="progress-box">
<template #header>
<div style="display:flex; justify-content:space-between;">
<span>处理进度</span>
<el-tag v-if="done" type="success">已完成</el-tag>
</div>
</template>
<p><strong>当前阶段:</strong>{{ stage || '处理中...' }}</p>
<el-progress
:percentage="percent"
:stroke-width="20"
text-inside
:status="percent === 100 ? 'success' : 'active'"
/>
</el-card>
<!-- 实时预览 -->
<div v-if="processedPages.length > 0" class="preview-container">
<el-card shadow="hover">
<div class="preview-header">
<div style="display: flex; align-items: center; gap: 15px;">
<span style="font-weight: bold;">实时预览</span>
<el-checkbox v-model="autoFollow" size="small" border>
自动跟随最新页
</el-checkbox>
</div>
<div class="page-nav">
<el-button size="small" @click="prevPage" :disabled="currentPreviewPage <= 1">
<el-icon><ArrowLeft /></el-icon>
</el-button>
<span>第 <el-input v-model.number="currentPreviewPageInput" size="small" @change="jumpToPage" /> / {{ processedPages.length }} 页</span>
<el-button size="small" @click="nextPage" :disabled="currentPreviewPage >= processedPages.length">
<el-icon><ArrowRight /></el-icon>
</el-button>
</div>
</div>
<div class="preview-layout">
<!-- 左侧:原图 -->
<div class="preview-panel">
<div class="preview-panel-header">
<span>原始图片</span>
<el-tag size="small" type="info">原图</el-tag>
</div>
<div class="preview-content">
<img v-if="currentOriginalImage" :src="currentOriginalImage" alt="原始图片">
<el-empty v-else description="加载中..." />
</div>
</div>
<!-- 右侧:PDF预览 (使用iframe) -->
<div class="preview-panel">
<div class="preview-panel-header">
<span>OCR 结果 (可复制文字)</span>
<el-tag size="small" type="success">可搜索PDF</el-tag>
</div>
<div class="preview-content" style="padding: 0;">
<iframe
v-if="currentPdfUrl"
:src="currentPdfUrl + '#toolbar=1&navpanes=0'"
width="100%"
height="100%"
style="border: none;"
></iframe>
<el-empty v-else description="等待处理..." />
</div>
</div>
</div>
</el-card>
</div>
<!-- 处理完成弹窗 -->
<el-dialog
v-model="showCompleteDialog"
title="🎉 处理完成"
width="400px"
:close-on-click-modal="false"
:show-close="false"
center
>
<div style="text-align: center; padding: 20px 0;">
<el-icon :size="60" color="#67c23a" style="margin-bottom: 15px;"><CircleCheck /></el-icon>
<p style="font-size: 16px; color: #606266; margin: 0;">
已生成 <strong style="color: #409eff;">{{ processedPages.length }}</strong> 页可搜索 PDF
</p>
</div>
<template #footer>
<div style="display: flex; justify-content: center; gap: 15px;">
<el-button type="primary" size="large" @click="download">
<el-icon style="margin-right: 5px;"><Download /></el-icon>
下载 PDF
</el-button>
<el-button size="large" @click="closeCompleteDialog">
再处理一个
</el-button>
</div>
</template>
</el-dialog>
</div>
</div>
<script>
const { createApp, ref, computed, watch, nextTick } = Vue
const app = createApp({
setup() {
// 步骤:upload -> select -> processing -> done
const step = ref('upload')
const taskId = ref('')
const pages = ref([])
const selectedPages = ref([])
const selectAll = ref(true)
const isVisible = ref(false) // 默认不勾选生成带原图背景
// 进度
const percent = ref(0)
const stage = ref('')
const done = ref(false)
const showCompleteDialog = ref(false)
// 预览
const processedPages = ref([])
const currentPreviewPage = ref(1)
const currentPreviewPageInput = ref(1)
const autoFollow = ref(true) // 默认开启自动跟随
const currentOriginalImage = computed(() => {
if (processedPages.value.length === 0) return ''
const page = processedPages.value[currentPreviewPage.value - 1]
return page ? `/preview/img/${taskId.value}/${page}` : ''
})
const currentPdfUrl = computed(() => {
if (processedPages.value.length === 0) return ''
const page = processedPages.value[currentPreviewPage.value - 1]
return page ? `/preview/pdf/${taskId.value}/${page}` : ''
})
// 同步input和实际页码
watch(currentPreviewPage, (val) => {
currentPreviewPageInput.value = val
})
// 自动跟随最新处理的页面
watch(processedPages, (pages) => {
if (autoFollow.value && pages.length > 0) {
// 自动跳转到最新处理的页面
currentPreviewPage.value = pages.length
}
}, { immediate: false })
const handleFileChange = async (fileItem) => {
if (!fileItem?.raw) return
const fd = new FormData()
fd.append('file', fileItem.raw)
const res = await fetch('/api/upload', {
method: 'POST',
body: fd
})
const data = await res.json()
if (data.task_id) {
taskId.value = data.task_id
pages.value = data.pages.map(p => ({
num: p.num,
thumb: `/preview/img/${data.task_id}/${p.num}`
}))
selectedPages.value = data.pages.map(p => p.num)
selectAll.value = true
step.value = 'select'
}
}
const handleSelectAll = (val) => {
if (val) {
selectedPages.value = pages.value.map(p => p.num)
} else {
selectedPages.value = []
}
}
const togglePage = (num) => {
const idx = selectedPages.value.indexOf(num)
if (idx > -1) {
selectedPages.value.splice(idx, 1)
} else {
selectedPages.value.push(num)
}
selectAll.value = selectedPages.value.length === pages.value.length
}
const startOcr = async () => {
step.value = 'processing'
// 发送OCR请求
const res = await fetch('/api/ocr', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
task_id: taskId.value,
pages: selectedPages.value,
visible: isVisible.value
})
})
listenSSE()
}
const listenSSE = () => {
const es = new EventSource(`/api/sse/${taskId.value}`)
es.onmessage = e => {
const d = JSON.parse(e.data)
percent.value = d.percent || 0
stage.value = d.stage || ''
// 更新已处理的页面列表
if (d.processed_pages) {
processedPages.value = d.processed_pages
// 如果是第一页处理完成,开始预览
if (processedPages.value.length === 1) {
currentPreviewPage.value = 1
}
}
if (d.done) {
done.value = true
es.close()
step.value = 'done'
// 显示完成弹窗
setTimeout(() => {
showCompleteDialog.value = true
}, 500)
}
}
}
const prevPage = () => {
if (currentPreviewPage.value > 1) {
currentPreviewPage.value--
autoFollow.value = false // 手动切换时关闭自动跟随
}
}
const nextPage = () => {
if (currentPreviewPage.value < processedPages.value.length) {
currentPreviewPage.value++
autoFollow.value = false // 手动切换时关闭自动跟随
}
}
const jumpToPage = () => {
let page = parseInt(currentPreviewPageInput.value)
if (isNaN(page)) page = 1
if (page < 1) page = 1
if (page > processedPages.value.length) page = processedPages.value.length
currentPreviewPage.value = page
// 用户手动跳转时,关闭自动跟随
autoFollow.value = false
}
const download = () => {
if (taskId.value && done.value) {
const a = document.createElement('a')
a.href = `/download/${taskId.value}`
a.download = `ocr_result_${taskId.value}.pdf`
a.click()
}
}
const reset = () => {
step.value = 'upload'
taskId.value = ''
pages.value = []
selectedPages.value = []
selectAll.value = true
isVisible.value = false
percent.value = 0
stage.value = ''
done.value = false
processedPages.value = []
currentPreviewPage.value = 1
currentPreviewPageInput.value = 1
showCompleteDialog.value = false
}
const closeCompleteDialog = () => {
showCompleteDialog.value = false
setTimeout(() => {
reset()
}, 300)
}
return {
step, taskId, pages, selectedPages, selectAll, isVisible,
percent, stage, done, showCompleteDialog, processedPages, currentPreviewPage, currentPreviewPageInput,
currentOriginalImage, currentPdfUrl, autoFollow,
handleFileChange, handleSelectAll, togglePage, startOcr,
prevPage, nextPage, jumpToPage, download, reset, closeCompleteDialog
}
}
})
/* 注册 Element Plus */
app.use(ElementPlus)
/* 注册 Icons */
Object.entries(ElementPlusIconsVue).forEach(([name, comp]) => {
app.component(name, comp)
})
app.mount('#app')
</script>
</body>
</html>
"""
@app.post("/api/upload")
async def upload(file: UploadFile):
"""上传PDF,渲染页面缩略图"""
tid = str(uuid.uuid4())
pdf_path = os.path.join(PDF_DIR, f"{tid}.pdf")
task_pages_dir = os.path.join(PAGES_DIR, tid)
os.makedirs(task_pages_dir, exist_ok=True)
try:
# 保存上传的PDF
with open(pdf_path, "wb") as f:
content = await file.read()
f.write(content)
except Exception as e:
raise HTTPException(status_code=500, detail=f"文件上传失败: {e}")
# 使用 PyMuPDF 渲染页面缩略图
try:
import fitz
doc = fitz.open(pdf_path)
pages = []
for i in range(len(doc)):
page_num = i + 1
img_path = os.path.join(task_pages_dir, f"page_{page_num:04d}.png")
# 渲染低分辨率缩略图用于预览
page = doc[i]
pix = page.get_pixmap(dpi=100)
pix.save(img_path)
pages.append({"num": page_num, "img": f"page_{page_num:04d}.png"})
doc.close()
return {
"task_id": tid,
"pages": pages
}
except Exception as e:
# 清理
if os.path.exists(pdf_path):
os.remove(pdf_path)
if os.path.exists(task_pages_dir):
shutil.rmtree(task_pages_dir)
raise HTTPException(status_code=500, detail=f"PDF渲染失败: {e}")
@app.post("/api/ocr")
async def ocr(data: dict):
"""启动OCR处理"""
tid = data.get("task_id")
pages = data.get("pages", [])
visible = data.get("visible", False)
if not tid or not pages:
raise HTTPException(status_code=400, detail="缺少task_id或pages")
pdf_path = os.path.join(PDF_DIR, f"{tid}.pdf")
out_path = os.path.join(OUT_DIR, f"{tid}.pdf")
task_pages_dir = os.path.join(PAGES_DIR, tid)
if not os.path.exists(pdf_path):
raise HTTPException(status_code=404, detail="PDF文件不存在")
# 保存配置
config = {
"pages": pages,
"visible": visible,
"total_pages": len(pages),
"processed": []
}
config_path = os.path.join(task_pages_dir, "config.json")
with open(config_path, "w", encoding="utf-8") as f:
json.dump(config, f)
# 启动OCR进程
cmd = [
"python",
"pdf_ocr_select.py",
"--pdf", pdf_path,
"--out", out_path,
"--task_id", tid,
"--workers", "4"
]
if visible:
cmd.append("--visible")
print(f"启动 OCR 进程: {' '.join(cmd)}")
try:
subprocess.Popen(cmd, stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL)
except Exception as e:
raise HTTPException(status_code=500, detail=f"启动处理进程失败: {e}")
return {"task_id": tid}
@app.get("/preview/img/{tid}/{page_num}")
async def preview_image(tid: str, page_num: int):
"""获取页面原图预览"""
img_path = os.path.join(PAGES_DIR, tid, f"page_{page_num:04d}.png")
if not os.path.exists(img_path):
raise HTTPException(status_code=404, detail="图片不存在")
return FileResponse(img_path, media_type="image/png")
@app.get("/preview/pdf/{tid}/{page_num}")
async def preview_pdf(tid: str, page_num: int):
"""获取单页PDF预览"""
pdf_path = os.path.join(PAGES_DIR, tid, f"ocr_page_{page_num:04d}.pdf")
if not os.path.exists(pdf_path):
raise HTTPException(status_code=404, detail="PDF页面不存在")
return FileResponse(pdf_path, media_type="application/pdf")
@app.get("/api/sse/{tid}")
def sse(tid: str):
def event_generator():
progress_file = f"{PROGRESS_DIR}/{tid}.json"
last_sent = None
while True:
if os.path.exists(progress_file):
try:
with open(progress_file, encoding="utf-8") as f:
data = json.load(f)
current = json.dumps(data, ensure_ascii=False)
if current != last_sent:
yield f"data: {current}\n\n"
last_sent = current
if data.get("done"):
break
except Exception:
pass
time.sleep(0.4)
return StreamingResponse(
event_generator(),
media_type="text/event-stream",
headers={
"Cache-Control": "no-cache",
"Connection": "keep-alive",
"X-Accel-Buffering": "no"
}
)
@app.get("/download/{task_id}")
async def download_file(task_id: str):
file_path = f"{OUT_DIR}/{task_id}.pdf"
if not os.path.exists(file_path):
raise HTTPException(status_code=404, detail="文件不存在或尚未完成处理")
# 检查进度文件是否存在且 done=True
progress_path = f"{PROGRESS_DIR}/{task_id}.json"
if os.path.exists(progress_path):
with open(progress_path, encoding="utf-8") as f:
progress = json.load(f)
if not progress.get("done"):
raise HTTPException(status_code=400, detail="处理尚未完成")
return FileResponse(
path=file_path,
filename=f"ocr_result_{task_id}.pdf",
media_type="application/pdf"
)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8038, reload=False)pdf_ocr_select.py
import os
import math
import argparse
import json
import cv2
import logging
import numpy as np
from pathlib import Path
from concurrent.futures import ThreadPoolExecutor, as_completed
from PIL import Image, ImageDraw, ImageFont
import fitz
from reportlab.pdfgen import canvas
from reportlab.lib.utils import ImageReader
from reportlab.pdfbase.ttfonts import TTFont
from reportlab.pdfbase import pdfmetrics
from reportlab.lib.colors import HexColor,Color
from tqdm import tqdm
import logging
from thread_single import PaddleOCRModelManager
# ① 初始化日志
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s [%(levelname)s] %(message)s"
)
# ② 构造 current_app(重点)
current_app = type(
"App",
(),
{"logger":logging.getLogger("PaddleOCR")}
)()
# ③ 使用
ocr_manager = PaddleOCRModelManager(current_app=current_app)
# ================== 配置 (对齐 1.py) ==================
BASE_DIR = Path(__file__).parent
TEMP_ROOT = BASE_DIR / "temp/pdf_pages"
PROGRESS_DIR = BASE_DIR / "temp/progress"
FONT_PATH_CN = BASE_DIR / "fonts/simsun.ttf"
USE_FONT_CN = "SimSun"
USE_FONT_EN = "Helvetica"
DEFAULT_DPI = 150 # 对齐 1.py 的 IMG_DPI
DEFAULT_WORKERS = 4
# 1.py 中的关键参数
IMG_DPI = 150
PDF_DPI = 150
PT_PER_INCH = 72
ZOOM_FACTOR = 2.0
TEXT_VERTICAL_OFFSET_PX = 10
MASK_PADDING_PX = 4
SCALE = 3
# ================== 命令行参数 ==================
parser = argparse.ArgumentParser()
parser.add_argument("--pdf", required=True, help="输入PDF路径")
parser.add_argument("--out", required=True, help="输出PDF路径")
parser.add_argument("--task_id", default="", help="任务ID,用于进度文件")
parser.add_argument("--dpi", type=int, default=DEFAULT_DPI)
parser.add_argument("--workers", type=int, default=DEFAULT_WORKERS)
parser.add_argument("--visible", action="store_true", help="是否显示原图背景 (True=有背景, False=纯白背景)")
parser.add_argument("--keep-temp", action="store_true", help="是否保留临时文件",default=True)
args = parser.parse_args()
input_pdf = Path(args.pdf).resolve()
output_pdf = Path(args.out).resolve()
task_id = args.task_id.strip()
DPI = args.dpi
MAX_WORKERS = max(1, min(args.workers, 8))
KEEP_TEMP = args.keep_temp
TEXT_VISIBLE = args.visible # 从命令行参数获取背景可见性
if not input_pdf.is_file():
logging.error(f"❌ 输入文件不存在: {input_pdf}")
exit(1)
temp_dir = Path(TEMP_ROOT) / task_id if task_id else Path(TEMP_ROOT) / input_pdf.stem
temp_dir.mkdir(parents=True, exist_ok=True)
# ================== 读取配置(页面选择)====================
config_path = temp_dir / "config.json"
selected_pages = None # None表示处理所有页面
if config_path.exists():
try:
with open(config_path, "r", encoding="utf-8") as f:
config = json.load(f)
selected_pages = config.get("pages")
logging.info(f"从配置读取到选择页面: {selected_pages}")
except Exception as e:
logging.warning(f"读取配置失败: {e}")
# ================== 进度报告 ==================
processed_pages_list = [] # 记录已处理的页面序号
def save_progress(percent: float, stage: str, done=False):
if not task_id:
print(f"[{percent:5.1f}%] {stage}")
return
pfile = Path(PROGRESS_DIR) / f"{task_id}.json"
pfile.parent.mkdir(parents=True, exist_ok=True)
data = {
"percent": round(percent, 1),
"stage": stage,
"done": done,
"processed_pages": processed_pages_list
}
try:
with open(pfile, "w", encoding="utf-8") as f:
json.dump(data, f, ensure_ascii=False)
except Exception as e:
logging.warning(f"保存进度失败: {e}")
logging.info(f"[{percent:5.1f}%] {stage}")
save_progress(0, "启动处理...")
# ================== 字体注册 ==================
if os.path.exists(FONT_PATH_CN):
try:
pdfmetrics.registerFont(TTFont(USE_FONT_CN, FONT_PATH_CN))
logging.info("中文字体注册成功")
except Exception as e:
logging.error(f"字体注册失败: {e},降级使用 Helvetica")
USE_FONT_CN = "Helvetica"
else:
USE_FONT_CN = "Helvetica"
logging.warning("未找到中文字体,降级使用 Helvetica")
def get_font_name(ch):
return USE_FONT_CN if '\u4e00' <= ch <= '\u9fff' else USE_FONT_EN
# ================== 1.py 字体适配逻辑 ==================
font_cache = {}
def get_font(size_pt: int):
size_pt = max(1, int(size_pt))
if size_pt not in font_cache:
font_cache[size_pt] = ImageFont.truetype(FONT_PATH_CN, size_pt)
return font_cache[size_pt]
def get_text_size(text, font):
dummy = Image.new("L", (1, 1))
draw = ImageDraw.Draw(dummy)
bbox = draw.textbbox((0, 0), text, font=font)
return bbox[2] - bbox[0], bbox[3] - bbox[1]
def fit_font_size_for_char(char: str, target_w_px: float, target_h_px: float) -> int:
if not char.strip(): return 12
lo, hi = 1, 2000
best = 12
target_w = target_w_px * PT_PER_INCH / PDF_DPI * SCALE
target_h = target_h_px * PT_PER_INCH / PDF_DPI * SCALE
for _ in range(25):
mid = (lo + hi) // 2
font = get_font(mid)
tw, th = get_text_size(char, font)
if tw <= target_w + 10 and th <= target_h + 10:
best, lo = mid, mid + 1
else:
hi = mid
return max(6, best // SCALE)
def fit_font_size(text: str, target_w_px: float, target_h_px: float) -> int:
if not text.strip(): return 12
lo, hi = 1, 2000
best = 12
target_w = target_w_px * PT_PER_INCH / PDF_DPI * SCALE
target_h = target_h_px * PT_PER_INCH / PDF_DPI * SCALE
for _ in range(25):
mid = (lo + hi) // 2
font = get_font(mid)
tw, th = get_text_size(text, font)
if tw <= target_w + 10 and th <= target_h + 10:
best, lo = mid, mid + 1
else:
hi = mid
return max(6, best // SCALE)
def px_to_pt(x_px, y_px, pdf_height_pt):
return x_px * PT_PER_INCH / PDF_DPI, pdf_height_pt - y_px * PT_PER_INCH / PDF_DPI
# ================== GPU 检测 ==================
# ================== 初始化 OCR (保持 130-137 的内容) ==================
save_progress(5, "加载 OCR 模型...")
OFFSET_PX = TEXT_VERTICAL_OFFSET_PX * ZOOM_FACTOR
def process_page(args_tuple):
"""单页 OCR 处理(线程中执行)"""
img_path, page_num, temp_dir_str = args_tuple
pdf_path = os.path.join(temp_dir_str, f"ocr_page_{page_num:04d}.pdf")
json_path = os.path.join(temp_dir_str, f"ocr_page_{page_num:04d}.json")
if os.path.exists(pdf_path) and os.path.exists(json_path):
return pdf_path, page_num
try:
# 使用全局 OCR 实例(多线程共享,GPU 友好)
text, raw = ocr_manager.submit_ocr(
input=img_path,
json_path=json_path
)
# 1.py 的 JSON 读取逻辑
with open(json_path, "r", encoding="utf-8") as f:
data = json.load(f)
texts = data["rec_texts"]
polys = data["rec_polys"]
# 1.py 的图片读取与缩放逻辑
orig_img = cv2.imread(img_path)
if orig_img is None: return None, page_num
img_h, img_w = orig_img.shape[:2]
img_w_zoom = int(img_w * ZOOM_FACTOR)
img_h_zoom = int(img_h * ZOOM_FACTOR)
pdf_width_pt = img_w_zoom * PT_PER_INCH / PDF_DPI
pdf_height_pt = img_h_zoom * PT_PER_INCH / PDF_DPI
c = canvas.Canvas(pdf_path, pagesize=(pdf_width_pt, pdf_height_pt))
if TEXT_VISIBLE:
# 背景图
img_zoom = cv2.resize(orig_img, (img_w_zoom, img_h_zoom), interpolation=cv2.INTER_LANCZOS4)
img_pil = Image.fromarray(cv2.cvtColor(img_zoom, cv2.COLOR_BGR2RGB))
c.drawImage(ImageReader(img_pil), 0, 0, width=pdf_width_pt, height=pdf_height_pt)
else:
# 白色背景
c.setFillColorRGB(1, 1, 1)
c.rect(0, 0, pdf_width_pt, pdf_height_pt, fill=1, stroke=0)
# 1.py 的文本层绘制逻辑
for text, poly in zip(texts, polys):
if not text.strip(): continue
box = np.array(poly, dtype=np.float32).reshape(4, 2) * ZOOM_FACTOR
x0, y0 = box.min(axis=0)
x1, y1 = box.max(axis=0)
w_box, h_box = x1 - x0, y1 - y0
angle_deg = np.degrees(np.arctan2(box[1][1] - box[0][1], box[1][0] - box[0][0]))
vertical = h_box > 2.5 * w_box and h_box > 120
if vertical:
chars = [ch for ch in text if ch.strip()]
if not chars: continue
per_char_w_px = w_box * 0.90
per_char_h_px = h_box * 0.80 / len(chars)
font_size_pt = min([fit_font_size_for_char(ch, per_char_w_px, per_char_h_px) for ch in chars] or [12])
gap_pt = max(2, font_size_pt * 0.30)
total_h_pt = len(chars) * font_size_pt + (len(chars) - 1) * gap_pt
total_h_px = total_h_pt * PDF_DPI / PT_PER_INCH
y_start_px = y0 + (h_box - total_h_px) / 2 + OFFSET_PX
cx_px = (x0 + x1) / 2
cur_y_px = y_start_px
for ch in text:
if not ch.strip(): continue
baseline_offset_px = font_size_pt * PDF_DPI / PT_PER_INCH / 2
x_pt, y_pt = px_to_pt(cx_px, cur_y_px + baseline_offset_px, pdf_height_pt)
c.saveState()
c.translate(x_pt, y_pt)
c.rotate(-angle_deg)
c.setFont(USE_FONT_CN, font_size_pt)
if TEXT_VISIBLE:
# 原图背景模式:变成幽灵文字
c.setFillAlpha(0.00)
#c.setFillColor(HexColor("#000000"))
c.setFillColor(Color(0, 0, 0, alpha=0)) # 完全透明
else:
c.setFillColor(HexColor("#000000"))
c.drawCentredString(0, 0, ch)
c.restoreState()
cur_y_px += (font_size_pt + gap_pt) * PDF_DPI / PT_PER_INCH
else:
font_size_pt = fit_font_size(text, w_box, h_box)
cx_px = (x0 + x1) / 2
cy_px = (y0 + y1) / 2 + OFFSET_PX
x_pt, y_pt = px_to_pt(cx_px, cy_px, pdf_height_pt)
c.saveState()
c.translate(x_pt, y_pt)
c.rotate(-angle_deg)
c.setFont(USE_FONT_CN, font_size_pt)
if TEXT_VISIBLE:
# 原图背景模式:变成幽灵文字
c.setFillAlpha(0.00)
## c.setFillColor(HexColor("#000000"))
c.setFillColor(Color(0, 0, 0, alpha=0)) # 完全透明
else:
c.setFillColor(HexColor("#000000"))
c.drawCentredString(0, 0, text)
c.restoreState()
c.showPage()
c.save()
return pdf_path, page_num
except Exception as e:
logging.error(f"页 {page_num} 处理出现异常: {e}", exc_info=True)
# 回退逻辑
try:
img = cv2.imread(img_path)
if img is not None:
h, w = img.shape[:2]
c = canvas.Canvas(pdf_path, pagesize=(w * 72 / DPI, h * 72 / DPI))
c.drawImage(ImageReader(img_path), 0, 0, width=w * 72 / DPI, height=h * 72 / DPI)
c.save()
except Exception as re:
logging.error(f"页 {page_num} 回退逻辑也失败了: {re}")
return pdf_path, page_num
# ================== 主流程 ==================
save_progress(10, "渲染 PDF 页面为图片...")
doc = fitz.open(str(input_pdf))
img_list = []
# 根据选择的页面过滤
total_pages = len(doc)
if selected_pages:
# 验证页面范围
valid_pages = [p for p in selected_pages if 1 <= p <= total_pages]
page_indices = [p - 1 for p in valid_pages] # 转换为0-based索引
logging.info(f"将处理选择的页面: {valid_pages}")
else:
page_indices = list(range(total_pages))
total_rendering = len(page_indices)
for idx, i in enumerate(page_indices):
page_num = i + 1 # 1-based页码
img_path = temp_dir / f"page_{page_num:04d}.png"
if not img_path.exists():
pix = doc[i].get_pixmap(dpi=DPI)
pix.save(str(img_path))
img_list.append((str(img_path), page_num, str(temp_dir)))
render_percent = 10 + (idx + 1) / total_rendering * 15
save_progress(render_percent, f"渲染页面 {page_num}/{total_pages}")
doc.close()
save_progress(25, f"启动 {len(img_list)} 页的 OCR 任务...")
tasks = img_list
page_pdfs = [None] * len(tasks)
page_nums = [None] * len(tasks)
count = 0
with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor:
future_to_idx = {executor.submit(process_page, t): i for i, t in enumerate(tasks)}
for future in tqdm(as_completed(future_to_idx), total=len(tasks), desc="OCR 处理"):
idx = future_to_idx[future]
try:
pdf_path, page_num = future.result()
page_pdfs[idx] = pdf_path
page_nums[idx] = page_num
# 记录已处理的页面
if page_num and page_num not in processed_pages_list:
processed_pages_list.append(page_num)
processed_pages_list.sort()
except Exception as e:
logging.error(f"进程执行任务时出错 (任务索引 {idx}): {e}", exc_info=True)
count += 1
ocr_percent = 25 + (count / len(tasks)) * 65
save_progress(ocr_percent, f"OCR 处理中 {count}/{len(tasks)}")
save_progress(90, "正在合并 PDF...")
final_doc = fitz.open()
for p in page_pdfs:
if p and os.path.exists(p):
src = fitz.open(p)
final_doc.insert_pdf(src)
src.close()
final_doc.save(str(output_pdf), garbage=4, deflate=True, clean=True)
final_doc.close()
if not KEEP_TEMP:
import shutil
shutil.rmtree(temp_dir, ignore_errors=True)
save_progress(100, "处理完成", done=True)
logging.info(f"✅ 完成!输出文件:{output_pdf}")运行
python main.py
转载作品,原作者:懒人程序,文章来源:https://mp.weixin.qq.com/s/OCZqH7Qcza9yx-4q8Cjefg